

oMLX menarik perhatian pengguna Mac karena menawarkan cara yang jauh lebih kencang untuk menjalankan model AI lokal di Apple Silicon. Dalam pengujian yang dikutip Better Stack, mesin ini mencatat 47 token per detik, sedangkan LM Studio berada di angka 16 token per detik.
Perbedaan itu membuat oMLX langsung dipandang sebagai opsi yang lebih agresif untuk beban kerja AI di Mac. Fokusnya bukan hanya pada kecepatan, tetapi juga pada efisiensi memori dan kelancaran saat beberapa aplikasi berjalan bersamaan.
Salah satu alasan utamanya ada pada pendekatan teknis yang dipakai. oMLX dibangun di atas framework MLX milik Apple, sehingga rancangan kerjanya lebih selaras dengan karakter Apple Silicon daripada solusi yang tidak dibuat khusus untuk ekosistem tersebut.
Di balik performanya, oMLX mengandalkan zero-copy arrays. Teknik ini mengurangi perpindahan data berulang antara CPU dan GPU, sehingga latensi dapat ditekan ketika proses AI sedang padat.
oMLX juga memakai strategi lazy computation. Dengan cara ini, perhitungan baru dijalankan saat benar-benar diperlukan, sehingga sumber daya tidak cepat habis dan respons real-time tetap terjaga.
Pendekatan tersebut membuat beban kerja berat terasa lebih stabil. Saat model AI lokal berjalan bersama aplikasi lain, sistem dirancang agar pengalaman multitasking tetap mulus dan tidak mudah tersendat.
Memori jadi pembeda besar
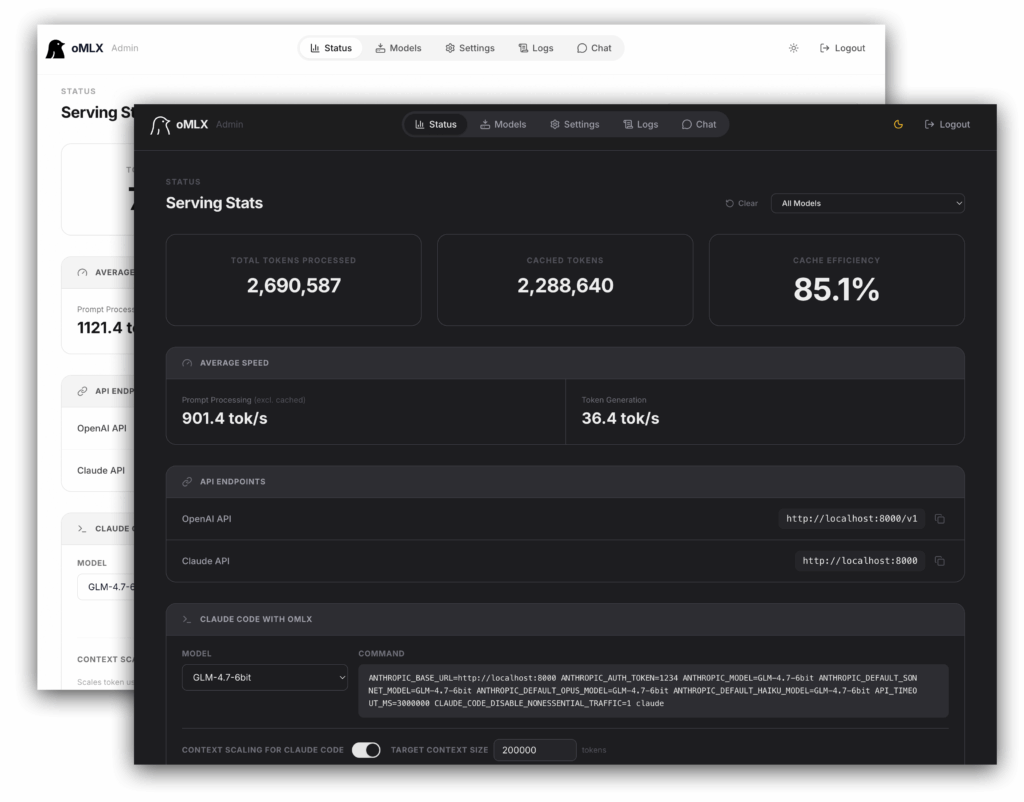
Selain dorongan di sisi kecepatan, pengelolaan memori menjadi nilai jual lain yang menonjol. oMLX memakai cache key-value dua lapis untuk menjaga keseimbangan antara akses cepat dan efisiensi alokasi sumber daya.
Konteks aktif disimpan di unified memory agar data yang sedang dipakai bisa diakses lebih cepat. Sementara itu, data yang lebih lama atau tidak mendesak dipindahkan ke cache SSD berkecepatan tinggi.
Skema ini membantu memangkas waktu tunggu pada tugas yang sedang berjalan. Dampaknya terasa terutama pada Mac dengan kapasitas memori terbatas karena tekanan pada RAM bisa berkurang.
Better Stack juga menyoroti bahwa cache di SSD bukan cuma soal performa. Penyimpanan itu membantu menjaga persistensi data, sehingga progres kerja lebih mudah dipulihkan jika terjadi penghentian mendadak.
Cocok untuk beban kerja panjang
Kemampuan oMLX tidak berhenti pada benchmark singkat. Dalam pengujian dunia nyata dengan model Qwen 3.6, sistem ini memproses 1,78 juta token dengan efisiensi cache mencapai 89 persen.
Angka itu menunjukkan oMLX mampu menangani komputasi skala besar dengan cukup efisien. Bagi pengguna yang menjalankan agen AI lokal atau eksperimen model besar di Mac, efisiensi cache seperti ini menjadi faktor penting.
Semakin baik cache bekerja, semakin kecil hambatan saat model harus mengambil konteks dan data yang relevan. Itulah alasan oMLX terlihat menarik untuk skenario kerja yang panjang dan kompleks.
Ada kompromi di balik performa
Meski unggul dalam kecepatan, oMLX tetap punya batasan. Salah satu yang disebut adalah munculnya error 400 ketika batas konteks terlampaui.
Dalam kondisi seperti itu, pengguna mungkin perlu membersihkan konteks secara manual. Situasi ini bisa mengganggu alur kerja, terutama saat sesi inferensi berlangsung panjang.
Di sisi lain, LM Studio disebut lebih stabil dalam pengelolaan konteks. Namun, keunggulan itu datang dengan konsekuensi berupa performa yang lebih lambat, sehingga kurang cocok untuk kebutuhan yang menuntut kecepatan tinggi.
Pengujian juga menunjukkan masih ada ruang pengembangan pada implementasi basis data untuk beberapa aplikasi. Artinya, meski mesin intinya sangat kuat, komponen pendukungnya belum sepenuhnya matang untuk semua kebutuhan.
Menarik untuk Mac dengan RAM terbatas
Manfaat paling terasa dari oMLX ada pada Mac yang RAM-nya tidak besar. Dengan memanfaatkan SSD berkecepatan tinggi untuk memperluas kemampuan memori, model AI lokal bisa tetap berjalan lebih mulus.
Pendekatan ini relevan bagi profesional yang membutuhkan komputasi berat maupun penggemar AI yang ingin menjalankan model secara lokal tanpa bergantung pada layanan cloud. Karena oMLX berfungsi sebagai server inferensi AI lokal, kehati-hatian tetap diperlukan meski proyek ini bersifat open source dan terlihat sah.
Pembatasan akses ke localhost dan penghindaran data sensitif tetap menjadi langkah yang masuk akal. Bagi pengguna Mac yang mengejar performa AI lokal setinggi mungkin di Apple Silicon, oMLX kini tampil sebagai pilihan yang sulit diabaikan.